작업하다가 UTF-8과 UTF-8 BOM과 관련해서 좀 문제가 생겼고, 그 과정에서 구글링하다 알게 된 것들이 있어 정리한다.
일단 늘 그렇듯 참고자료.
BOM(Byte Order Mark)은 UTF-8(혹은 16/32)로 인코딩된 문서의 인코딩 방식을 식별하기 위해 파일 맨 앞에 붙는 2~4바이트의 식별코드이다.
일단 내가 헷갈렸다가 이번에 확인한 것들을 정리하자면…
UTF-8 BOM과 UTF-8은 맨 앞의 3바이트 식별코드 외에는 동일하다. 코드페이지도 둘다 65001이며, 다른 인코딩 방식이 아니다. 이게 같은 파일을 어떤 툴은 그냥 UTF-8이라고 하고 어떤 툴은 UTF-8 BOM이라고 해서 헷갈렸는데, 그냥 전자가 BOM을 따로 분류해주지 않을 뿐이었다.
Visual Studio는 문서를 UTF-8 BOM으로만 저장할 수 있다. VS 2017/2019는
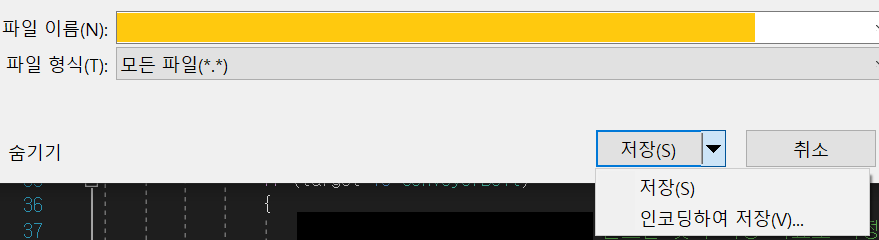
파일-다른 이름으로 저장에서 저장 버튼 옆의 팝업을 클릭하면 인코딩을 바꿔 저장할 수 있다.![인코딩 변경]() 여기서 확인해보면 UTF-8 BOM만 있다. 즉, 최소한 윈도우판 Visual Studio 2017/2019는 UTF-8 without BOM을 따로 지원하지 않는다.
여기서 확인해보면 UTF-8 BOM만 있다. 즉, 최소한 윈도우판 Visual Studio 2017/2019는 UTF-8 without BOM을 따로 지원하지 않는다.UTF-8 without BOM을 인식하는 확실하고 표준화된 방법은 없다. 양키들은 문제없다고 하지만 그건 영어권 사용자들 이야기고요. 한국어 인코딩(CP949), 일본어 인코딩(Shift-JIS)으로 저장된 문서를 UTF-8 without BOM과 구분하지 못하는 툴은 의외로 흔하다.
당연하지만 VS2019도 구분 못해서 다 깨짐.이 포스팅을 쓰게 된 이유지만, 윈도우 버전 SourceTree에서 유니티 프로젝트를 관리할 경우는 UTF-8 BOM을 쓰는 것이 좋아 보인다.
 여기서 확인해보면 UTF-8 BOM만 있다. 즉, 최소한 윈도우판 Visual Studio 2017/2019는 UTF-8 without BOM을 따로 지원하지 않는다.
여기서 확인해보면 UTF-8 BOM만 있다. 즉, 최소한 윈도우판 Visual Studio 2017/2019는 UTF-8 without BOM을 따로 지원하지 않는다.따로 설명해야 할 건 4인데, 일단 SourceTree는 EUC-KR이나 CP949로 저장된 파일을 제대로 출력하지 못한다. 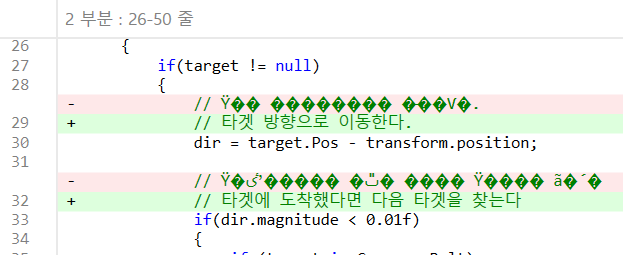
위 파일은 EUC-KR로 저장되어 있었던 코드를 UTF-8로 바꾼 결과이다.
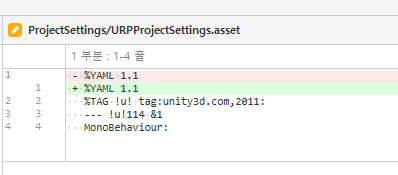
그리고 텍스트 형식으로 저장하는 유니티의 씬이나 프리팹, 에셋 등을 UTF-8 without BOM으로 저장하면 이걸 바이너리 파일로 인식해버리는 경우가 있었다. 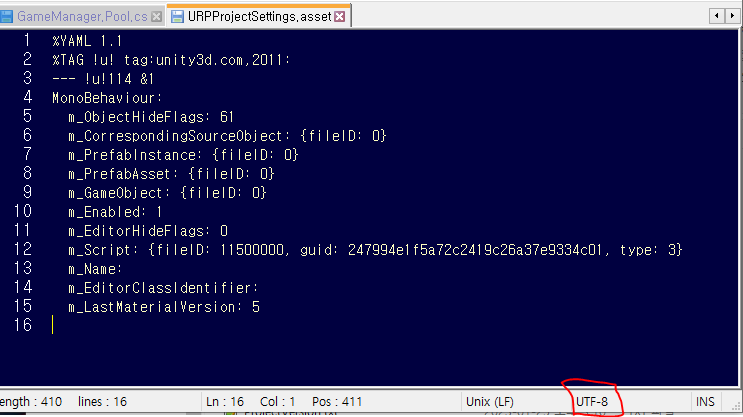
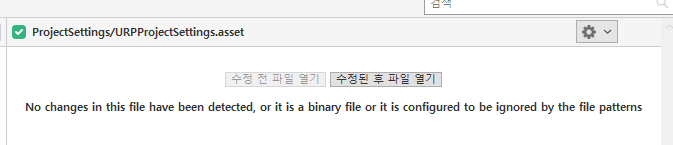
이러면 diff가 안 보이므로 상당히 불편해진다. UTF-8 BOM으로 인코딩을 변경하면 SourceTree가 파일을 정상적으로 텍스트로 인식한다.
졸려서 좀 횡설수설하는 것 같지만 요약하자면…
한국어나 다른 외국어가 들어간 파일을 윈도우에서만 쓸 경우, UTF-8 BOM으로 저장하는 게 더 좋다. 리눅스/유닉스 시스템에서 쓴다면 이야기가 다르겠지만.
유니티 씬이나 프리팹 파일을 SourceTree가 바이너리라고 인식할 경우, UTF-8 BOM으로 인코딩을 바꾸면 해결된다.
UTF-8 외의 인코딩으로 저장된 소스 파일이 있으면 싹 바꾸자. 대체 왜 있는진 모르겠지만 변환툴을 돌려보니 의외로 많이 나와서 놀랐다.
그리고 번외지만, JSON 파일에는 BOM을 넣지 않는 것이 원칙인 듯.
내 개발환경에서는 이게 딱히 문제가 된 적은 없지만 주의할 필요는 있을 것 같다.